

Get Started with Sandbox
Here is the summary of the steps for setting up Apache Eagle (called Eagle in the following) in Hortonworks sandbox:
- Step 1: Setup sandbox image in a virtual machine
- Step 2: Setup Hadoop1 environment in sandbox
- Step 3: Download and extract a Eagle release to sandbox
- Step 4: Install Eagle
- Step 5: Stream HDFS audit log
Step 1: Setup sandbox image in a virtual machine
To install Eagle on a sandbox you need to run a HDP sandbox image in a virtual machine with 8GB memory recommended.
- Get Virtual Box or VMware Virtualization environment
- Get Hortonworks Sandbox v 2.2.4
Step 2: Setup Hadoop environment in sandbox
- Launch Ambari2 to manage the Hadoop environment
- Enable Ambari in sandbox http://127.0.0.1:8000 (Click on Enable Button)
- Login to Ambari UI http://127.0.0.1:8080/ with username and password as “admin”
- Grant root as HBase3 superuser via Ambari
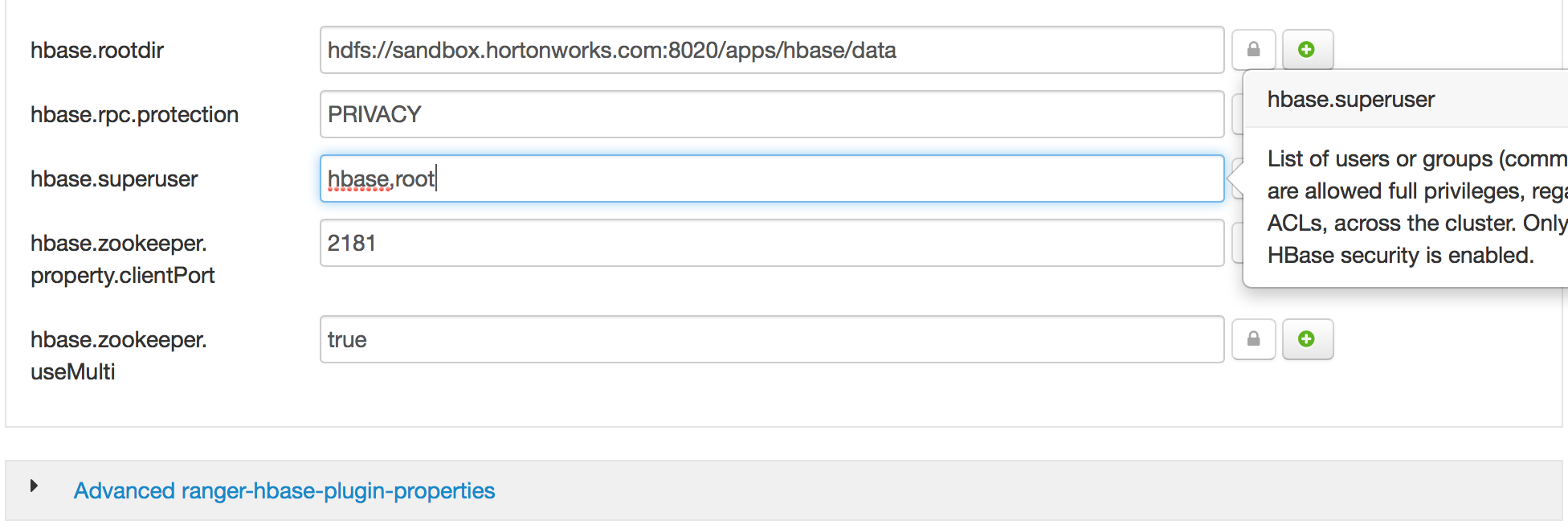
- Start Storm4, HBase & Kafka5, Ambari. Showing Storm as an example below.

Step 3: Download and extract a Eagle release to sandbox
-
Download
-
Option 1: Download eagle jar from here.
-
Option 2: Build form source code eagle github. After successful build, ‘eagle-xxx-bin.tar.gz’ will be generated under
./eagle-assembly/target# installed npm is required before compiling $ mvn clean install -DskipTests=true
-
-
Copy and extract the package to sandbox
#extract $ tar -zxvf eagle-0.1.0-bin.tar.gz $ mv eagle-0.1.0 /usr/hdp/current/eagle
Step 4: Install Eagle in Sandbox
The following installation actually contains installing and setting up a sandbox site with three data sources HdfsAuditLog, HiveQueryLog, and User Profiles
-
Option 1: Install Eagle using command line
$ cd /usr/hdp/current/eagle $ examples/eagle-sandbox-starter.sh -
Option 2: Install Eagle using Eagle Ambari plugin
Step 5: Stream HDFS audit log
To stream HDFS audit log into Kafka, the last step is to install a namenode log4j Kafka appender (another option Logstash is here).
-
Step 1: Configure Advanced hadoop-log4j via Ambari UI, and add below “KAFKA_HDFS_AUDIT” log4j appender to hdfs audit logging.
log4j.appender.KAFKA_HDFS_AUDIT=org.apache.eagle.log4j.kafka.KafkaLog4jAppender log4j.appender.KAFKA_HDFS_AUDIT.Topic=sandbox_hdfs_audit_log log4j.appender.KAFKA_HDFS_AUDIT.BrokerList=sandbox.hortonworks.com:6667 log4j.appender.KAFKA_HDFS_AUDIT.KeyClass=org.apache.eagle.log4j.kafka.hadoop.AuditLogKeyer log4j.appender.KAFKA_HDFS_AUDIT.Layout=org.apache.log4j.PatternLayout log4j.appender.KAFKA_HDFS_AUDIT.Layout.ConversionPattern=%d{ISO8601} %p %c{2}: %m%n log4j.appender.KAFKA_HDFS_AUDIT.ProducerType=async #log4j.appender.KAFKA_HDFS_AUDIT.BatchSize=1 #log4j.appender.KAFKA_HDFS_AUDIT.QueueSize=1
-
Step 3: Edit Advanced hadoop-env via Ambari UI, and add the reference to KAFKA_HDFS_AUDIT to HADOOP_NAMENODE_OPTS.
-Dhdfs.audit.logger=INFO,DRFAAUDIT,KAFKA_HDFS_AUDIT
-
Step 4: Edit Advanced hadoop-env via Ambari UI, and append the following command to it.
export HADOOP_CLASSPATH=${HADOOP_CLASSPATH}:/usr/hdp/current/eagle/lib/log4jkafka/lib/*
-
Step 5: save the changes and restart the namenode.
-
Step 6: Check whether logs are flowing into topic
sandbox_hdfs_audit_log$ /usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic sandbox_hdfs_audit_log
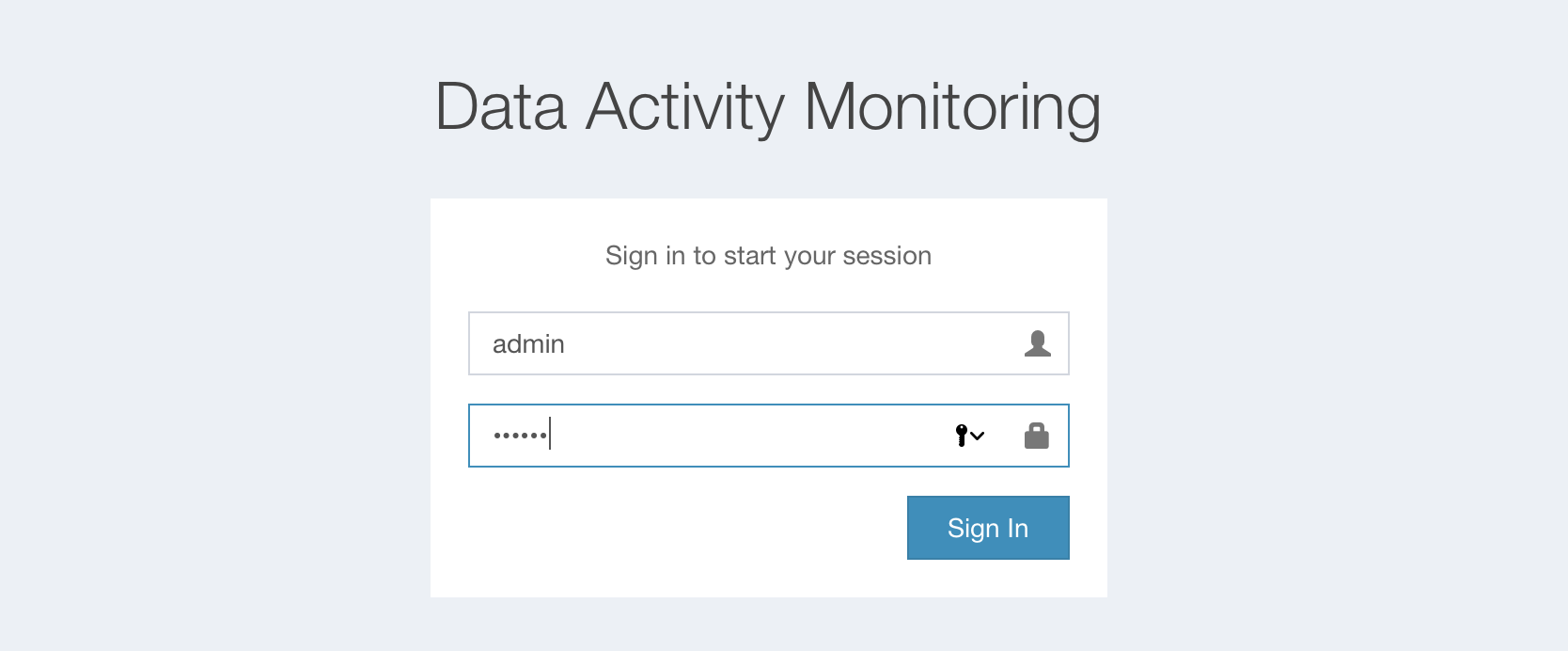
Now please login to Eagle web http://localhost:9099/eagle-service with account admin/secret, and try the sample demos on
Quick Starer
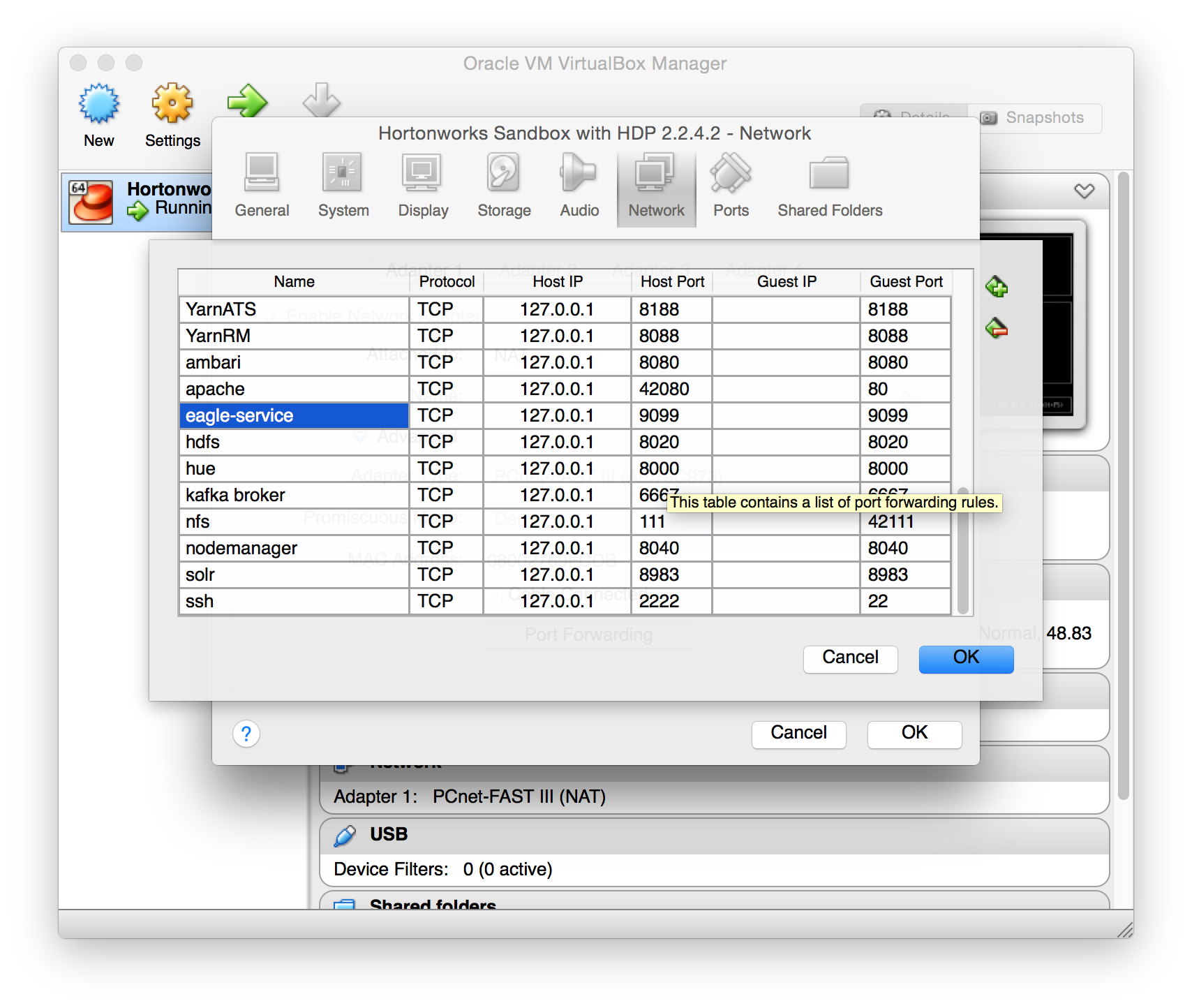
(If the NAT network is used in a virtual machine, it’s required to add port 9099 to forwarding ports)
Footnotes
-
All mentions of “hadoop” on this page represent Apache Hadoop. ↩
-
All mentions of “ambari” on this page represent Apache Ambari. ↩
-
All mentions of “hbase” on this page represent Apache HBase. ↩
-
All mentions of “storm” on this page represent Apache Storm. ↩
-
All mentions of “kafka” on this page represent Apache Kafka. ↩